Starting
11.2, Oracle introduced a new feature called In-Memory parallel execution. This
allows parallel slaves to do full segment scans via the buffer cache (and not
via direct path reads). Note that this feature is not related to the 12c database
in-memory option.On
the face of it, it appears to be a nice little feature that allows you to cache
a big table across the buffer cache of all RAC instances. But on Exadata, your query
will not take advantage of smart scans, storage indexes, column projections because
these features need direct path read as a prerequisite.
So, the
next question that immediately comes to mind is – which is better? A parallel
query doing buffered reads or a parallel query doing smart scans. Let’s get
started with a little demo. IMPX
kicks in when parallel_degree_policy is set to AUTO and the segment size is between
2-80% of the global buffer cache. There could be other heuristics and algorithms
that impacts Oracle decision to use direct reads or buffered reads.
In
this set up, I’ve a table T of size 26 GB. I’m on an Exadata X7 machine, using a 3 node RAC. Each node has buffer cache size of 20
GB. Therefore, global buffer cache size is 60 GB. Database version is 11.2.0.4
Scenario
1 : parallel_degree_policy is set to MANUAL. IMPX does not kick in.
SQL>
SELECT /*+ PARALLEL(8) */ COUNT(*) FROM T ;
This SQL has a wall clock time of 1 second. Looking at the execution stats
SELECT
inst_id,
elapsed_time / 1e6,
executions,
buffer_gets,
disk_reads,
ROUND(physical_read_bytes / 1024 / 1024 / 1024,2) physical_read_gb,
ROUND(IO_CELL_OFFLOAD_ELIGIBLE_BYTES / 1024 / 1024 / 1024,2) IO_CELL_OFFLOAD_ELIGIBLE_GB,
ROUND(IO_INTERCONNECT_BYTES / 1024 / 1024 / 1024,2) IO_INTERCONNECT_GB,
ROUND(IO_CELL_UNCOMPRESSED_BYTES/1024/1024/1024,2) IO_CELL_UNCOMPRESSED_GB,
ROUND(100*(IO_CELL_OFFLOAD_ELIGIBLE_BYTES -
IO_INTERCONNECT_BYTES)/IO_CELL_OFFLOAD_ELIGIBLE_BYTES,2) IO_SAVED_PERC
FROM gv$sql
WHERE sql_id = 'aavvpznpcf8b7'
ORDER BY 1
inst_id,
elapsed_time / 1e6,
executions,
buffer_gets,
disk_reads,
ROUND(physical_read_bytes / 1024 / 1024 / 1024,2) physical_read_gb,
ROUND(IO_CELL_OFFLOAD_ELIGIBLE_BYTES / 1024 / 1024 / 1024,2) IO_CELL_OFFLOAD_ELIGIBLE_GB,
ROUND(IO_INTERCONNECT_BYTES / 1024 / 1024 / 1024,2) IO_INTERCONNECT_GB,
ROUND(IO_CELL_UNCOMPRESSED_BYTES/1024/1024/1024,2) IO_CELL_UNCOMPRESSED_GB,
ROUND(100*(IO_CELL_OFFLOAD_ELIGIBLE_BYTES -
IO_INTERCONNECT_BYTES)/IO_CELL_OFFLOAD_ELIGIBLE_BYTES,2) IO_SAVED_PERC
FROM gv$sql
WHERE sql_id = 'aavvpznpcf8b7'
ORDER BY 1

** Click on the image to have clear view.
As you can see, total disk reads is about 26 GB. And almost all of it is eligible for offloading.
IO_SAVED_PERC is at 99%. This indicates that a smart scan has taken place. Only a few MBs of data was transferred back from the cell server to the database compute node. This explains why the SQL was so quick. This is the hardware capability of Exadata. Its ability to scan 26 GB of data at cell server in less than a second. AWSOME ! Isn't it ?
IO_SAVED_PERC is at 99%. This indicates that a smart scan has taken place. Only a few MBs of data was transferred back from the cell server to the database compute node. This explains why the SQL was so quick. This is the hardware capability of Exadata. Its ability to scan 26 GB of data at cell server in less than a second. AWSOME ! Isn't it ?
Scenario 2: parallel_degree_policy is set to AUTO. IMPX kicks in.
SQL> alter system set parallel_degree_policy=AUTO SCOPE=BOTH SID='*' ;
Now we run the same select again.
SQL> SELECT /*+ PARALLEL(8) */ COUNT(*) FROM T ;
Now the SQL wall clock time went up drastically from 1 second to 8 minutes and 45 seconds.
Here are the execution stats
Here are the execution stats

IO_CELL_OFFLOAD_ELGIBLE_BYTES is now 0. And around 26 GB of data has been sent back from the cell server to the database compute node. It was a buffered read, smart scans did not take place. Let's look at V$BH to see if the blocks has been cached across all the RAC instances.
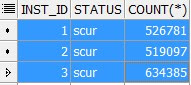
SELECT inst_id, status, COUNT (*)
FROM gv$bh
WHERE objd = 66837983 AND status != 'free'
GROUP BY inst_id, status
ORDER BY 2 DESC
FROM gv$bh
WHERE objd = 66837983 AND status != 'free'
GROUP BY inst_id, status
ORDER BY 2 DESC
T
These are the number of blocks cached on each of the instances in scur mode.
Adding the number of blocks - 1680263. Multiplied by DB Block size of 16KB- I get 26 GB.
Oracle has now uniformly cached the entire table in the buffer cache of instance 1,2,3. Each instance caches around 8 GB of data blocks. This was done using cell multiblock physical reads (and not via cell smart scans). This explains why this execution took more than 8 minutes. It had to read 25 GB of data from the storage, transfer it to the compute nodes and cache it onto the instance buffer cache. This is certainly an overhead for the first execution.
Now let's run the same SQL again. Hoping that this time, Oracle would read the data from the global buffer cache.
SQL> SELECT /*+ PARALLEL(8) */ COUNT(*) FROM T ;
And yes, second execution of this SQL completes in 1 second. Looking at the stats

No smart scans here as io_cell_offload_eligible_bytes is 0. But disk reads and physical reads bytes has come down to 0. Because Oracle can now find all the block it needs in the buffer cache of instance 1,2,3. Another important point to note here is that the PX servers do not use cache fusion to transfer blocks between nodes. It is also possible to see one instance doing direct path reads and other instance(s) going for buffered reads.
To summarise this behaviour, IMPX is not really useful on Exadata environments because it prevents the use of smart scans and storage indexes. Queries that benefits a lot from smart scans will most likely suffer from parallel buffered reads. Moreover, the global database cache is still limited in size, couple of big tables in a warehouse environment can easily fill up 80% of the cache and then Oracle will start to trash the cache. That's again a huge overhead.
In my opinion, AUTO parallel degree policy is like a beast in the cage. It makes your database vulnerable to IMPX, parallel statement queuing and as a DBA you are never in complete control ! It is best to have the policy set to MANUAL specially for large warehouse databases on Exadata environments.


No comments:
Post a Comment